MLP
MLP(multi-layer perceptrons),中文就是多层感知机、多层全连接神经网络,可以看成是基于生物神经元的抽象模型。在层之间,利用激活函数处理数据,使得学习能力增强。MLP模型需要做的往往就是需要花费较长的时间去训练模型中的参数:每层的权重和偏置。方法是使用梯度下降法去调整参数。
前馈神经网络就是由全连接神经网络+多层MLP组成,相当于有向无环图。(+有参数的图)
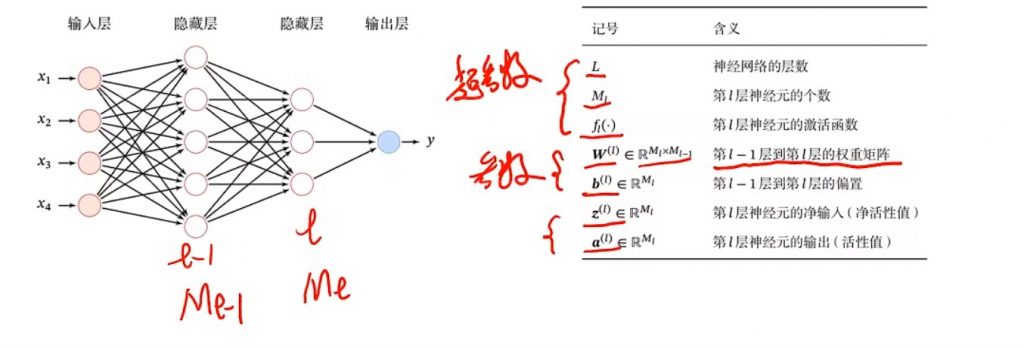
反向传播算法就是可以用第l层的梯度计算第l-1层的损失函数光遇参数的梯度。简单的就是对损失项+正则项去对参数求导优化参数。参数一般是权重和偏置。神经网络中一般都是向量和矩阵的求导。
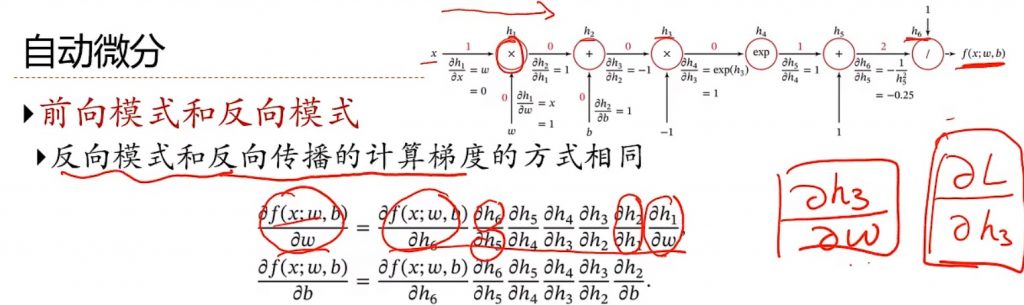
神经网络的优化方法还有更加通用的方法:自动微分(AD)。其实就是机器自动计算链式法则求导。(+图)
softmax分类器,softmax函数就可以将k个标量转化为据有k个取值的分布,可以出来一个连续的每个类的概率的分布,相当于pθ。用于交叉熵损失中,pθ是我们估计的概率,要逼近的目标是真实的pr。还有一个KL散度,没太理解清楚。(+图)

RBM
受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)是一种可用随机神经网络(stochastic neural network)来解释的概率图模型(probabilistic graphical model)。无向图结点分两类,观测变量和隐藏变量
数学基础概念:受限玻尔兹曼机(RBM)学习笔记(一)预备知识_皮果提的博客-CSDN博客
BP神经网络
一种按照误差逆向传播算法训练的多层前馈神经网络,系统解决了多层神经网络隐含层连接权学习问题。BP神经网络的计算过程由正向计算过程和反向计算过程组成。
CNN模型
就是卷积+池化。其中,每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。
RNN模型
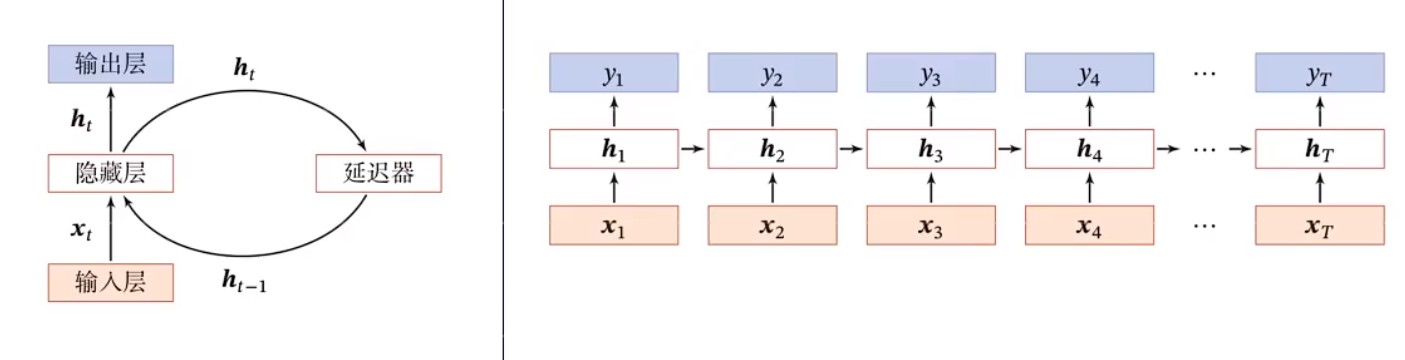
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)。只要考虑时间先后顺序的问题都可以使用RNN来解决。所以损失函数是对应时刻计算损失函数然后总和。带自反馈的神经元,能够处理任意长度的时序数据。但是重新看图,我并没有看出循环的点在哪里。
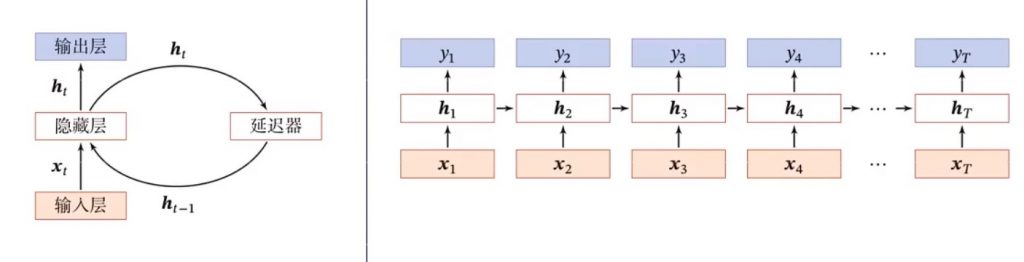
?带有Attention的Encoder-Decoder模型。
BPTT(back-propagation through time)算法是常用的训练RNN的方法,其实本质还是BP算法,只不过用RNN处理时间序列数据,所以要基于时间反向传播,故叫随时间反向传播。
?RNN的梯度计算是真的没看懂,所以不知道如何解释梯度消失与梯度爆炸。(参数学习和长程依赖问题)
由于时间维度太深,存在长程依赖问题,可以只保留xt与ht的非线性关系,h之间变成线性关系,但是会使得模型能力变差。所以变线性的同时,把ht-1放回激活函数里。现在又产生新的问题:如果激活函数算的是正数,那么ht会越来越大。
!RNN是图灵完备的。还有增加RNN的并行能力也很重要。
RNN的应用:从一个序列到另一个序列的机器翻译,就是拿一个RNN做encoder、另一个RNN做decoder。当然也可以图片到文本的翻译。
LSTM
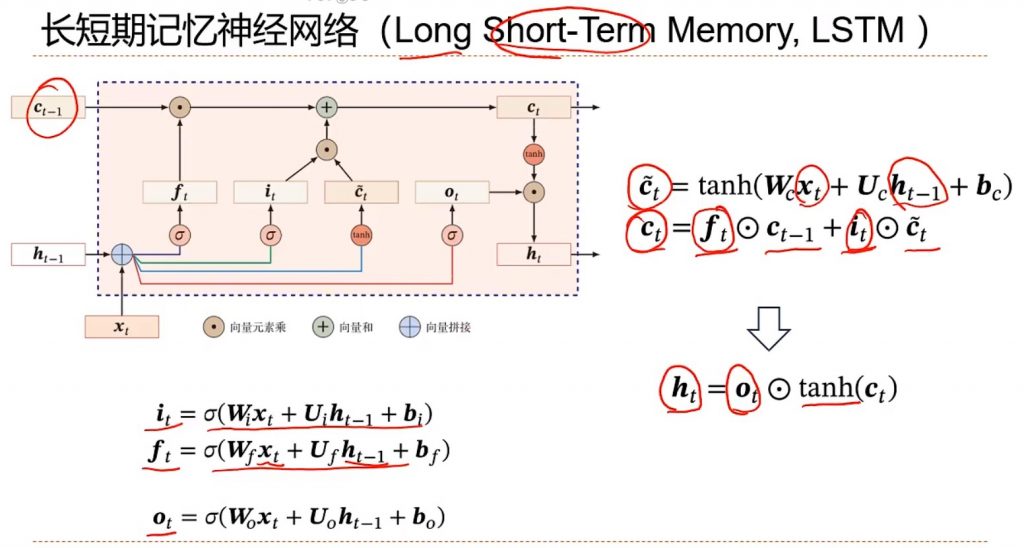
由于RNN也有梯度消失的问题,因此很难处理长序列的数据,大牛们对RNN做了改进,得到了RNN的特例LSTM(Long Short-Term Memory),长短期记忆神经网络,它可以避免常规RNN的梯度消失。LSTM引入多一个记忆单元,之前是已经有一个h,现在由新的C来做线性的信息的传递,h就继续传递非线性的内容,大大提高了RNN的建模能力。然后还引入由三个门来控制细胞状态,这三个门分别称为遗忘门f、输入门i和输出门。f和i都是可以通过自己的权重与xt和ht-1算出来的。输入门和候选的Ct相乘,遗忘门就和之前的Ct-1相乘,C经过非线性处理后再×输出门就得到最新的h。(图)
GRU
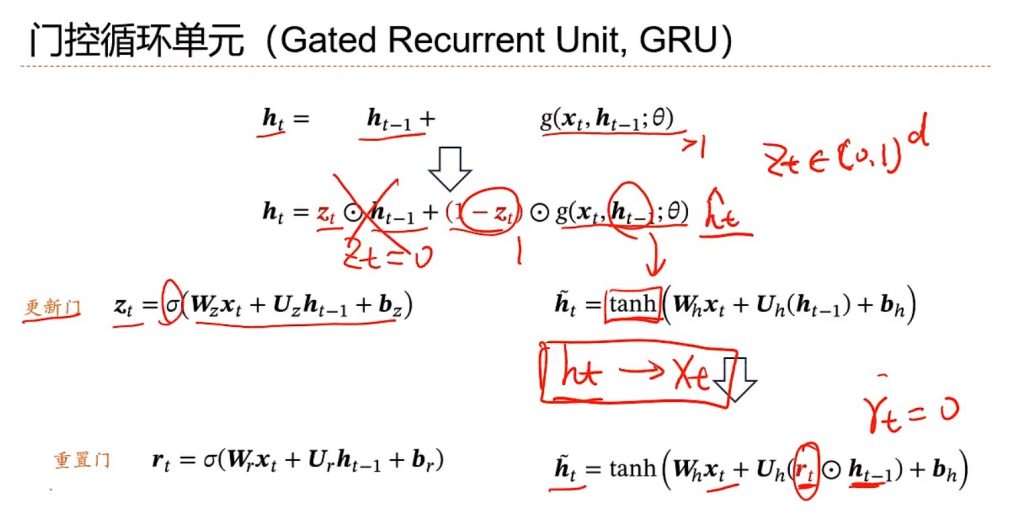
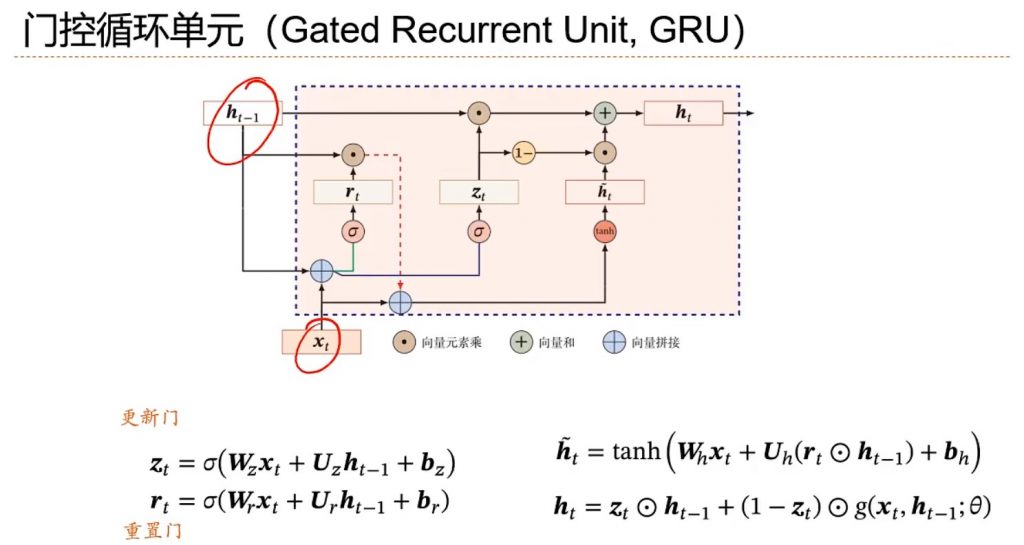
GRU(Gate Recurrent Unit)是循环神经网络(RNN)的一种,是门控循环单元。他引入了门控机制,可以控制信息的累计速度,选择地加入新信息,也可以实现遗忘信息的功能。
引入新向量Z,也叫更新门。他的每一维度都是在0-1之间。如果等于0,就相当于忘掉前一个h携带的信息,然后彻底依赖后面新产生的信息。新信息的变换一般用tanh去变换,tanh斜率梯度大,不容易产生斜率消失的问题。有时候还会引入重置门使得ht只与当前时刻状态xt有关(图)
如果想让循环神经网络在非时间维度上变深的模型,有堆叠循环神经网络、双向循环模型,可以使得隐含的信息更多。
神经网络的优化难点:
- 结构差异大
- 超参数多
- 非凸优化问题,得找全局最优解,高维就叫鞍点,低维就叫驻点
- 如何初始化参数
残差连接可以使得地形优化地更加平缓。
随机梯度是按照梯度的反方向更新参数,可以进行小批量随机梯度下降。
Adam动态调节学习率。
提高神经网络的泛化能力:
- 干扰优化过程:早停法、暂退法、权重衰减、SGD
- 增加约束:正则项l1和l2
暂退法:引入一个随机的掩码函数,将一些神经元给隐藏掉,训练的是dropout后的子网络。如果有n个神经元,可以采样出2的n次方个子网络。这里涉及到从贝叶斯学习角度去分析意义,但是我不是很懂,对参数θ的采样,Θ是啥来着?
正则化的时候提到了范数,l1和l2范数,要小于等于1。正则化系数越大,越接近线性,也就是对模型的泛化能力约束越强。l2正则化也是会利用权重衰减进行参数的更新的呀,我以为就是不变的正则项。
网络部件(运用到任意神经网络)
注意力机制
两种注意力,自下而上的pooling和自上而下的focus。然后又分hard attention和soft attention,soft attention就是引入打分机制来对关注第n个信息的概率进行打分,找出最像的。因为要把求出打分函数处理后的结果进行分布处理观察嘛,所以很容易想到softmax。
不过有个疑问,最后把所有分布权加起来了,那一个总的结果,怎么看到底选出哪个概率呢?为啥不是max出最好的概率捏?(图)
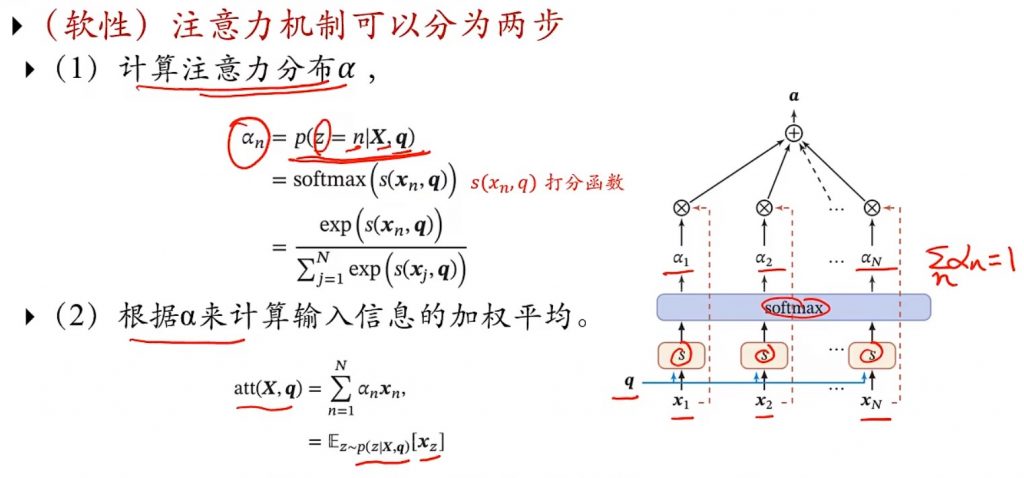
打分函数S(Xn,q)也有几种的,
那么把连续的分布变成离散的分布,就是hard attention。由于是离散的,硬性注意力就没有梯度,所以通常结合强化学习来把他看作连续的决策过程。
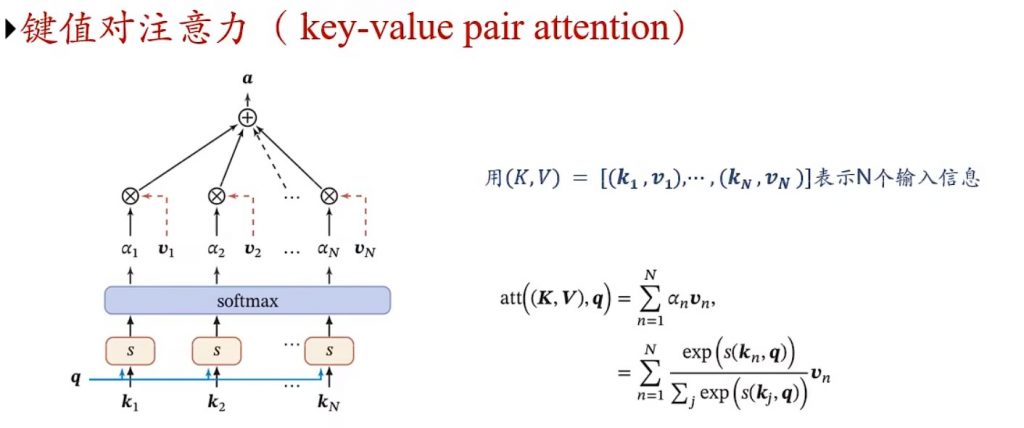
键值对注意力机制,用key经过softmax函数做概率分布α,再拿α和v做结果的汇总。键计算相似度,值进行汇总,相当于功能分离了。为啥分离就更强大了呢?(图)
指针网络:只需要找出和任务相关的信息在哪里就行了。不需要加权汇总了。
通过注意力机制可以降低RNN模型的复杂度,他就不用关注太多任务相关的内容,只负责建立通用的表示。比如不用在意关注的是情感问题还是分类问题了。机器翻译的encode和decode里也可以结合attention,可以充当词对齐作用来提高机器翻译的能力。attention就是主要看上下文?
上面说到的q就是外部的查询向量,需要人为提供。而在自注意力模型里的q就是自己,在句子内做attention,得到这个词的上下文相关表示,不需要外部传递。softmax得到注意力矩阵。首先计算第n个词对其他词的权重,hn就是第n个词的上下文表示。
transformer:把每个位置编码成一个向量,然后把词向量加起来,新的x就能考虑距离和内容的相关度。层归一化,能使得层更深,transformer是全连接的,建立了任意两个词之间的依赖关系,不停迭代得到每个词的上下文表示。
结构化的外部记忆:是一个矩阵来的,主控网络通过注意力机制进行寻址,再到确定的外部记忆单元进行读写。不是很懂,一般记忆什么呢?记录各种状态和特征嘛?图灵机->可微分图灵架构机
联想记忆,分自联想和异联想,可以更好地增加网络的数据容量。