用户输入
用户在地址栏按下回车,浏览器会检查输入,看看是否符合URL规则。当前页面调用执行onbeforeunload事件,浏览器进入加载状态。
URL请求发送到提交数据
浏览器是一个客户端,它会发起请求,具体是浏览器进程通过IPC(进程间通信)把URL请求发送至网络进程。最开始,浏览器先查找缓存,在浏览器中查询是否有请求的文件。当浏览器发现请求的资源已经在浏览器缓存中有副本,它会拦截请求并返回该资源的副本,直接结束请求。如果没有这个缓存,就进行DNS解析。浏览器向本地DNS服务器咨询URL中主机服务器它的域名所对应的ip地址,期间也会先查询DNS缓存,当DNS域名服务器返回ip地址后,浏览器拿该ip地址和Web服务器建立TCP连接之后,浏览器发送HTTP请求(如果是HTTPS,还需要建立TLS),要求获取URL中指定的那个资源文件,Web服务器返回被请求的文件,TCP连接就释放。
以下有一些可以展开的点:
DNS解析
识别主机可以通过主机名或者IP地址。我们一般喜欢记忆主机名,比如www.google.com 。路由器喜欢IP地址。DNS可以提供从主机名转化为IP地址的目录服务。
IP地址(例如127.7.106.83)由4个字节组成,是有着严格的层次结构的。
DNS是:①一个由分层的DNS服务器实现的分布式数据库;②一个使得主机能够查询分布式数据库的应用层协议;③基于域的命名方案。
检查DNS缓存
想获得的IP地址通常也会缓存在“附近的”DNS服务器中,因为在一个请求链中,当某DNS服务器接受一个DNS回答(包含主机名到IP地址的映射),它能将此映射缓存在本地。所以有时候我们无须访问主机名的权威服务器就能获取到IP地址。所以DNS解析的时候会先检查DNS缓存。
浏览器在一定时间内维护DNS记录的缓存,如果浏览器有记录,可以直接使用。浏览器没有,再检查操作系统缓存,因为操作系统也维护DNS记录的缓存。如果你的计算机没有缓存,那么它会搜索路由器,因为路由器也有DNS记录的缓存。如果上述三处都找不到IP地址,则在ISP(互联网服务提供商)保存的DNS记录缓存中查找。如果这里也没有找到,那么ISP的DNS递归搜索就完成了。在“DNS递归搜索”中,一个DNS服务器发起一个DNS查询,与其他几个DNS服务器通信以找到IP地址。
TCP连接
TCP提供的是面向连接的服务。任何采用了TCP的应用,都会在正式传输数据之前,搭建这根TCP逻辑连接。Chrome有个机制,同一个域名同时最多建立6个TCP连接,多的请求需要进入排队等待状态。排队结束后,客户端和服务器就可以“握手”了。
TCP三次握手建立连接
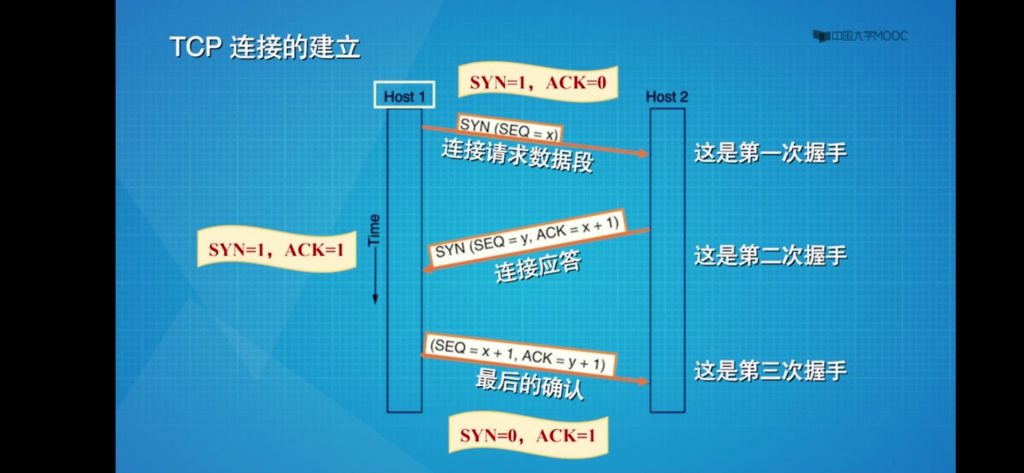
- 第一次握手:SYN 连接请求数据段,包含初始序列号x,它是由客户端随机产生的。控制位SYN=1、ACK=0,整个SYN就叫做第一次握手信息
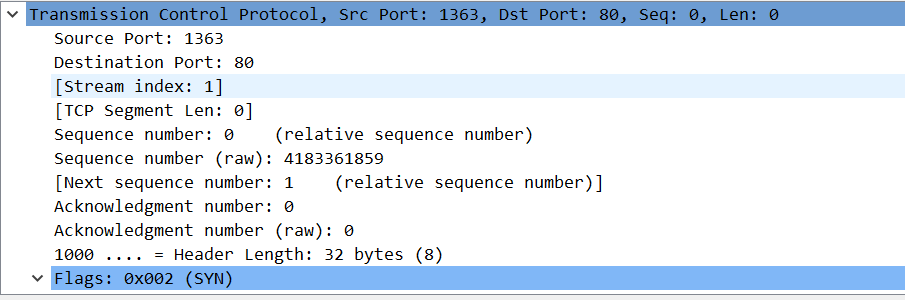
- 第二次握手:客户端收到服务端的SYN,会回发一个连接应答,也叫SYN,里面包含了初始序列号y,由Host2服务器随机产生。控制位SYN=1、ACK=1。同时确认号ACK number=x+1,表示对host1的x号字节的确认。这是第二次握手信息。
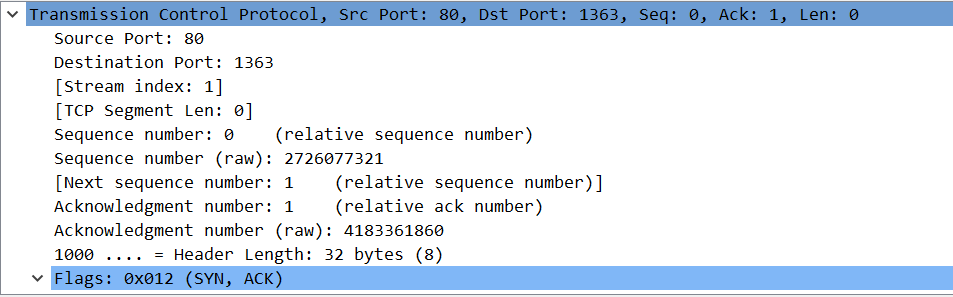
- 第三次握手:当连接应答到达Host1客户端,Host1客户端发送最后的确认,包含序列号等于x+1,确认号等于y+1,控制位SYN=0\ACK=1。这是第三次握手信息。
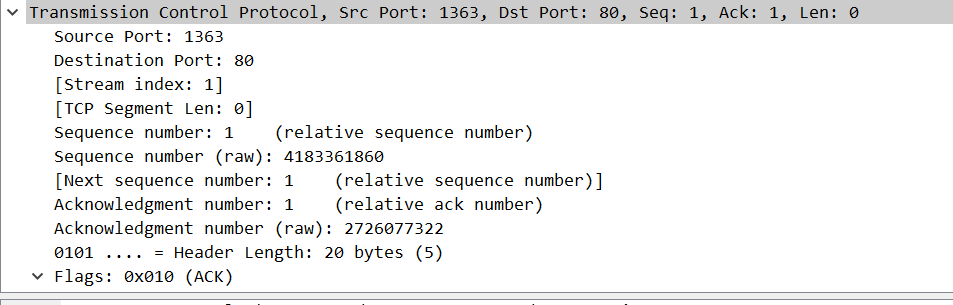
三次握手也被称为同步,这个过程,双方交换了最重要的参数,就是初始序列号,可以用来跟踪后续交换的每一个字节。

图:利用抓包工具查看到的握手报文截图
服务端处理和返回HTTP响应
当TCP连接建立好了,浏览器和服务器就开始使用HTTP交流。当用户请求一个Web页面时,浏览器向服务器发出对该页面中所包含对象的HTTP请求报文,服务器接收到请求并用包含这些对象的HTTP响应报文进行响应。
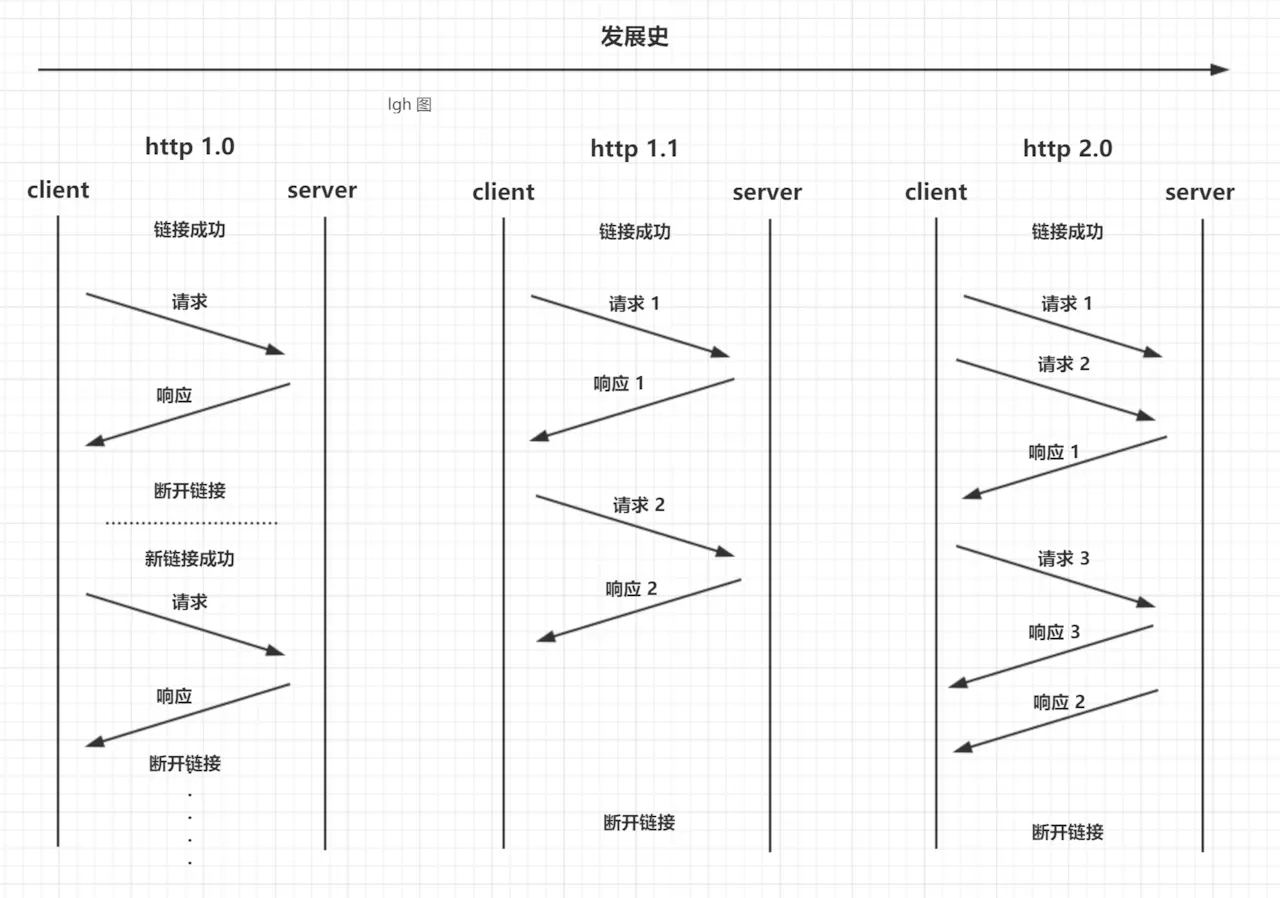
HTTP(超文本传输协议)是浏览器与服务器之间的通信语言,其基于TCP协议。HTTP早期用来学术交流,也被称为超文本传输协议,专门用来传递HTML超文本的内容。因为浏览器的推广,HTTP/1.0通过请求头和响应头支持多种不同类型的数据。除此之外,还引用了状态码、Cache机制、用户代理。接着,出现了HTTP/1.1增加了长连接特性,一个TCP可以传输多个HTTP请求,节省了新建 TCP 连接握手的时间。
然而,HTTP/1.1对带宽的利用率不高,还有慢启动和TCP连接之间相互竞争带宽。接着我们迎来了HTTP2,其最具颠覆的就是多路复用机制,一个域名只使用一个TCP长连接,有效避免对头阻塞问题。还有就是采取二进制分帧层,可以将请求分为一帧一帧的数据去传输,每份数据都有ID。下面有张来自别人总结的图,真的画得很清晰明了。
那么HTTP响应报文是怎样的呢,以下是我在wireshark抓包到的浏览器的请求报文和服务器的响应报文。
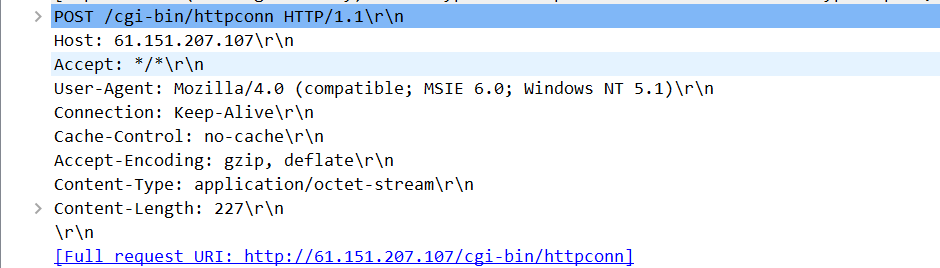
HTTP请求报文的第一行叫作请求行,其后继的行叫作首部行。请求行有3个字段:方法字段、URL字段、URL字段和HTTP版本字段。方法字段代表着请求方法,比如GET、POST、HEAD、PUT等等。我这个是POST,表示要发送一些数据给服务器。首部行指明了对象所在的主机。User-agent:首部行用来指明用户代理,即服务器发送请求的浏览器类型。

响应报文的第一行是初始状态行,接着下面是首部行,最后是实体体(就是页面内容了,图中没有),所以实体体部分是报文的主要部分。
状态行有3个字段:协议版本字段、状态码和相应状态信息。比如图中表示服务器正在使用HTTP/1.1,而且可以看到状态码200告诉我们一切正常。
- 状态码含义
- 1XX:接受的请求正在处理
- 2XX:请求正常处理完毕
- 3XX:重定向,要附加操作
- 4XX:客户端请求出错,服务器无法处理请求
- 5XX:服务器处理请求出错
再看看首部行,Server表示这个报文又这个服务器产生。Connection就是发送完报文要不要关闭TCP连接,像例子中的keep-alive就是保持打开状态,浏览器可继续通过此TCP连接发送请求。Content-type就是指示实体体中的对象是什么类型。Content-1ength指示了被发送对象的字节数。
不过有时候,我们输入baidu.com时,页面地址最终显示的是www.baidu.com, URL的转变是由于重定向操作。比如响应报文中的响应行的状态码是301时,就是告诉浏览器要重定向,同时还会返回一个Location字段方便浏览器重新导航。有时候没有Location字段,就得自个手动重新输入了。
页面显示
网络进程在接受到响应头之后,会根据响应头中的content-type判断,如果是“text/html”,那么浏览器会选择创建一个渲染进程。Chrome 的默认策略是,每个标签会对应一个渲染进程。但如果从一个页面打开了另一个新页面,而新页面和当前页面属于同一站点的话,那么新页面会复用父页面的渲染进程。
提交文档
接着浏览器会进入“提交文档”阶段,这一阶段会更新浏览器导航的内容:安全状态、前进后退的历史状态、并更新Web界面:原来的页面会先变成一片空白。此时标识浏览器加载状态的小圈圈,从此前URL网络请求时的逆时针转动,变成顺时针转动,正式进入渲染解析阶段。
构建DOM树
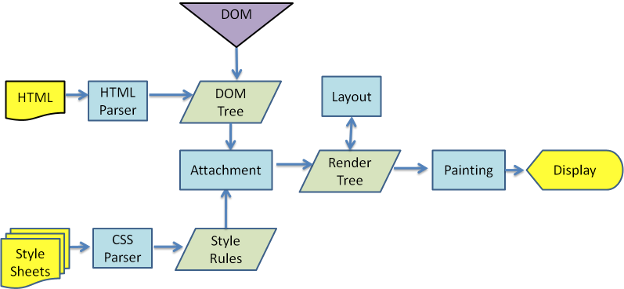
浏览器获得响应,此时网络进程和渲染进程会建立一个共享数据通道,浏览器进程将网络进程接收到的HTML 数据提交给渲染进程。因为浏览器是读不懂HTML的,所以浏览器渲染引擎里的HTML解析器会将HTML转化为浏览器能理解的结构——DOM树。在没有完整接受全部HTML文档时,HTML解析器就开始工作了。
通过在控制台输入document查看DOM结构,发现DOM和HTML内容几乎一样。不过和HTML不同的是,DOM是保存在内存中的树状结构,可以通过Javascript来查询或者修改内容。也就是说DOM是生成页面的基础数据结构,提供给Javascript脚本操作的接口。
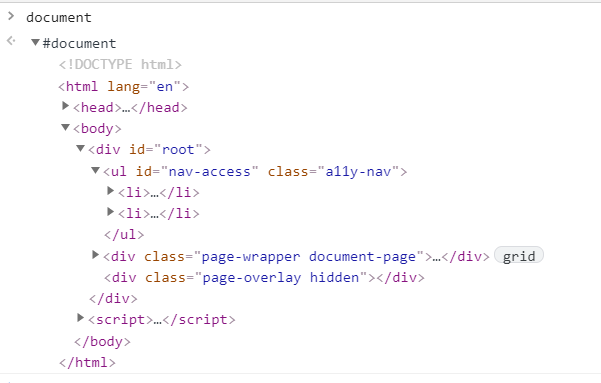
在解析过程,如果遇到请求外部资源时,请求过程是异步的,并不会影响html文档加载,举个例子,外部CSS文件的加载,不会影响DOM树的构建。
构建styleSheets、样式计算和布局
接着,浏览器如果在解析过程中遇到CSS样式,包括link外部引用的、<style>标签内的和内嵌的CSS,它都会把CSS转化为浏览器能够理解的结构——styleSheets。样式表准备好了,浏览器会转化样式表中的属性值,比如把颜色统一转化为rgb的。接着计算出DOM树中每个节点的样式属性。最后创建布局树和计算DOM元素的集合坐标位置这些布局信息。

构建图层树
到了绘制阶段,渲染引擎的绘制是按照图层树一层一层绘制的,所以会先根据DOM构建出一个图层树。渲染引擎会为有以下特点的节点生成专用的图层,无图层的DOM节点属于父节点图层。
- 拥有层叠上下文属性(明确定位属性、透明属性、z-index、css滤镜等)的元素
- 需要剪裁的地方
经过分块和栅格化后合成绘制
渲染引擎接着将图层树中的每个图层进行绘制,并生成绘制列表提价给合成线程,合成线程会将较大和较长的图层划分为图块(256 * 256/512 * 512),按照视口附近的图块优先生成位图。实际生成位图的操作是由栅格化(光栅化)来执行的。栅格化就是将图块转换为位图。最后合成线程再将绘制图块命令(DrawQuad)交给浏览器进程,浏览器进程根据绘制命令生成页面,就是将所有图层合成为可以显示的页面图片,并显示到显示器上。
其它概念
重绘(repaint)和回流(reflow)
页面在首次加载时必然会经历reflow和repaint。如果通过JavaScript或者CSS修改元素的几何位置属性,例如改变元素的宽度、高度等,浏览器会触发重新布局,也叫回流。回流包含了前面的各种计算,所以开销是最大的。
如果没有更改元素的几何位置属性,只是更改了如背景颜色,那么就叫做重绘,那么可以跳过计算布局阶段,直接开始绘制,执行效率稍微比回流高。
回流一定会触发重绘,而重绘不一定会回流。
减少这两个的操作,可以通过:
- 使用class操作样式,而不是频繁操作style
- 避免使用table布局
- 批量dom操作,比如使用框架React
- 对dom属性的读写要分离
- will-change:transform做优化
- 触发repaint和reflow的操作尽量放在一起
Javascript影响DOM
当执行到Javascript时,需要先下载Javascript代码,停止整个DOM的解析。所以Javascript文件的下载过程会阻塞DOM解析。也就是会阻塞页面的渲染。有时候我们还会用JavaScript操作元素样式,所以JavaScript脚本又是依赖样式表的,所以CSS也有可能阻塞页面的渲染。所以常常说,应该把CSS放在文档头部,JS文件放在文档尾部。
总结
搜索“输入url,发生了什么?”,网上有许多总结得很好的文章。但是我还是想自己总结一下,总结起来发现会更有自己的思路了。不过,从网络请求到整个页面呈现,真的涉及到好多好多内容,包括网络部分、浏览器工作原理等等,涉及到的每一点都可以写成一篇文章。这篇文章就当给自己对于这个问题的一个回答了。
参考和学习资料:
② 书籍《计算机网络 自顶向下方法》
③ 慕课大学 华南理工大学《计算机网络》 袁华 等